Welcome to Jan Nano Docs

We spent on the money on GPU - so here is a blank HTML docs page.
Overview
Jan-Nano is a compact 4-billion parameter language model specifically designed and trained for deep research tasks. This model has been optimized to work seamlessly with Model Context Protocol (MCP) servers, enabling efficient integration with various research tools and data sources.
Demo

Jan-Nano is supported by Jan, an open-source ChatGPT alternative that runs entirely on your computer. Jan provides a user-friendly interface for running local AI models with full privacy and control.
System Requirements
- Minimum Requirements:
- 8GB RAM (with iQ4_XS quantization)
- 12GB VRAM (for Q8 quantization)
- CUDA-compatible GPU
- Recommended Setup:
- 16GB+ RAM
- 16GB+ VRAM
- Latest CUDA drivers
- RTX 30/40 series or newer
Setup Guidelines
Quick Start
- Install Jan Beta
- Download Jan-Nano from Hub
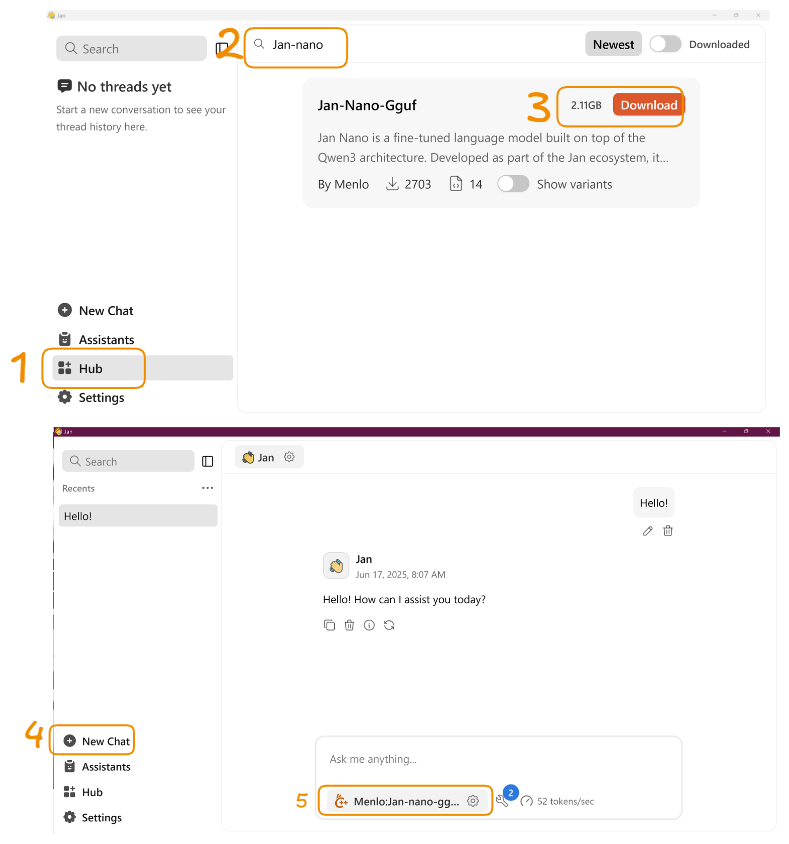
- Start new chat with Jan-Nano
MCP Server (Serper) Setup
- Recommended: Serper MCP Server
- Requirements: Node.js ≥ 18, Serper API key (get your API key here)
Using with Jan
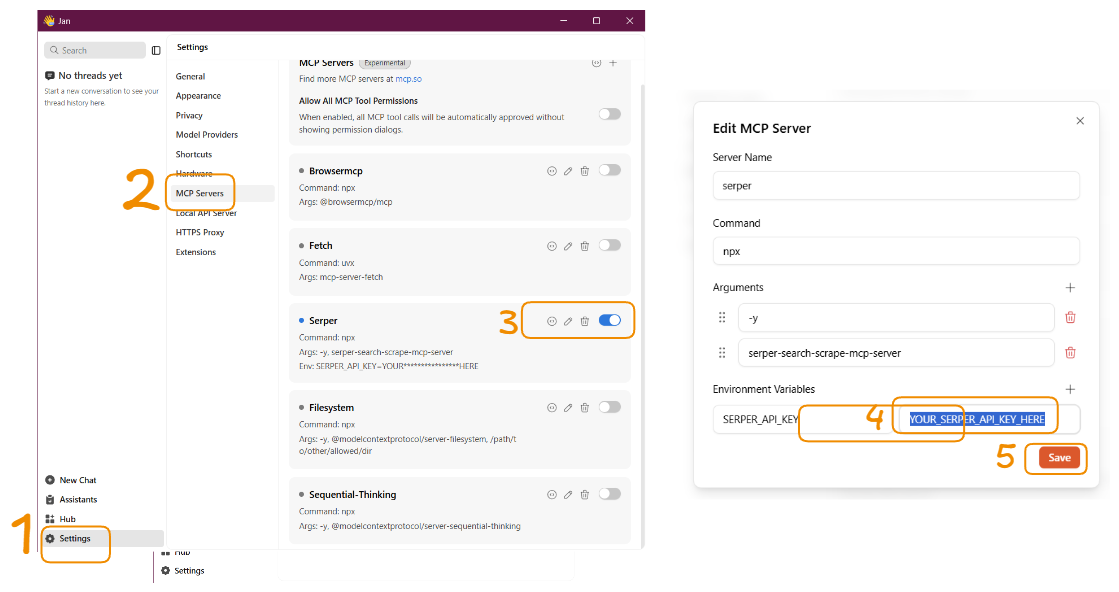
- Start the Serper MCP server as above.
- In Jan, go to Settings → MCP Servers.
-
Add a new MCP server, set the command to:
env SERPER_API_KEY=your_api_key_here npx -y serper-search-scrape-mcp-server - Save and ensure Jan can connect to the MCP server.
Performance
Jan-Nano has been evaluated on the SimpleQA benchmark using our MCP-based benchmark methodology:

The evaluation was conducted using our MCP-based benchmark approach, which assesses the model’s performance on SimpleQA tasks while leveraging its native MCP server integration capabilities. This methodology better reflects Jan-Nano’s real-world performance as a tool-augmented research model.
FAQ
- What are the recommended GGUF quantizations?
- Q8 GGUF is recommended for best performance
- iQ4_XS GGUF for very limited VRAM setups
- Avoid Q4_0 and Q4_K_M as they show significant performance degradation
- Can I run this on a laptop with 8GB RAM?
- Yes, but use the recommended quantizations (iQ4_XS)
- Note that performance may be limited with Q4 quantizations
- How much did the training cost?
- Training was done on internal A6000 clusters
- Estimated cost on RunPod would be under $100 using H200
- Hardware used:
- 8xA6000 for training code
- 4xA6000 for vllm server (inferencing)
- What frontend should I use?
- Jan Beta (recommended) - Minimalistic and polished interface
- Download link: https://jan.ai/docs/desktop/beta
- Getting Jinja errors in LM Studio?
- Use Qwen3 template from other LM Studio compatible models
- Disable “thinking” and add the required system prompt
- Fix coming soon in future GGUF releases
- Having model loading issues in Jan?
- Use latest beta version: Jan-beta_0.5.18-rc6-beta
- Ensure proper CUDA support for your GPU
- Check VRAM requirements match your quantization choice
Resources
Contact
- For support, questions, and community chat, join the Menlo Discord Community